
What are the Processing Dynamics of Music and Speech Compression
Richard Honeycutt demonstrates beautifully through graphs and a listening track the processing dynamics of music and speech compression.
The variation in sound level, from very quiet to very loud, or from pianissimo to fortissimo in music, is called the dynamic range of the sound. In a fairly quiet living room, the background noise may be about 30 dBA. A good sound-reproducing system, whether solid- or hollow-state, will produce less background noise in the listening room than will the ambient noise sources: HVAC, traffic, people, birds and crickets, etc.
The maximum sound level to which we should ever expose our ears, even for very brief periods, is 120 dBA.
- The dynamic range of pretty good modern home-listening conditions is about 90 dB (=120 dBA-30 dBA).
- An excellent concert hall may have an additional 15 dB, because of lower background noise. (Even a full audience can be very quiet, as people often hold their breath during pianissimo passages.)
- The old 78-RPM lacquer records had a dynamic range of about 40 dB when new, but this quickly degenerated to about 30 dB because of the increase of surface noise with wear.
- An LP record can have a dynamic range of about 65 dB.
- Reel-to-reel tape, without noise reduction applied, has a dynamic range of about 60 dB, and cassette tapes are not quite as good, at 50-56 dB.
- Theoretically, a CD has a maximum dynamic range of 96 dBA, but in practice this depends upon a number of circuitry variables.
- Music streamed through a computer is limited at the bottom by the background noise in the room—30 dBA at the lowest, ranging to perhaps 60 dBA if children are playing or kitchen appliances are used in an adjacent room, or if a neighbor is mowing the lawn.
- The maximum level of excellent computer speakers is about 110 dB at 1 meter distance in a good listening room. Thus the dynamic range for streamed music can vary from 50 to 80 dB.
“Compression” of music refers to reducing the dynamic range. One type of compression involves gain reduction when the input voltage exceeds the threshold. This is called “downward compression”, since the gain is adjusted downward in response to an increase in input level. There is also “upward compression”, in which the gain is increased when the input voltage drops below the threshold. Figure 1 shows a characteristic curve incorporating upward compression for input signals (horizontal axis) below -40 dBFS (dB full-scale, where 0 dBFS is the maximum “digital level”), transitioning gradually to downward compression at higher input levels.
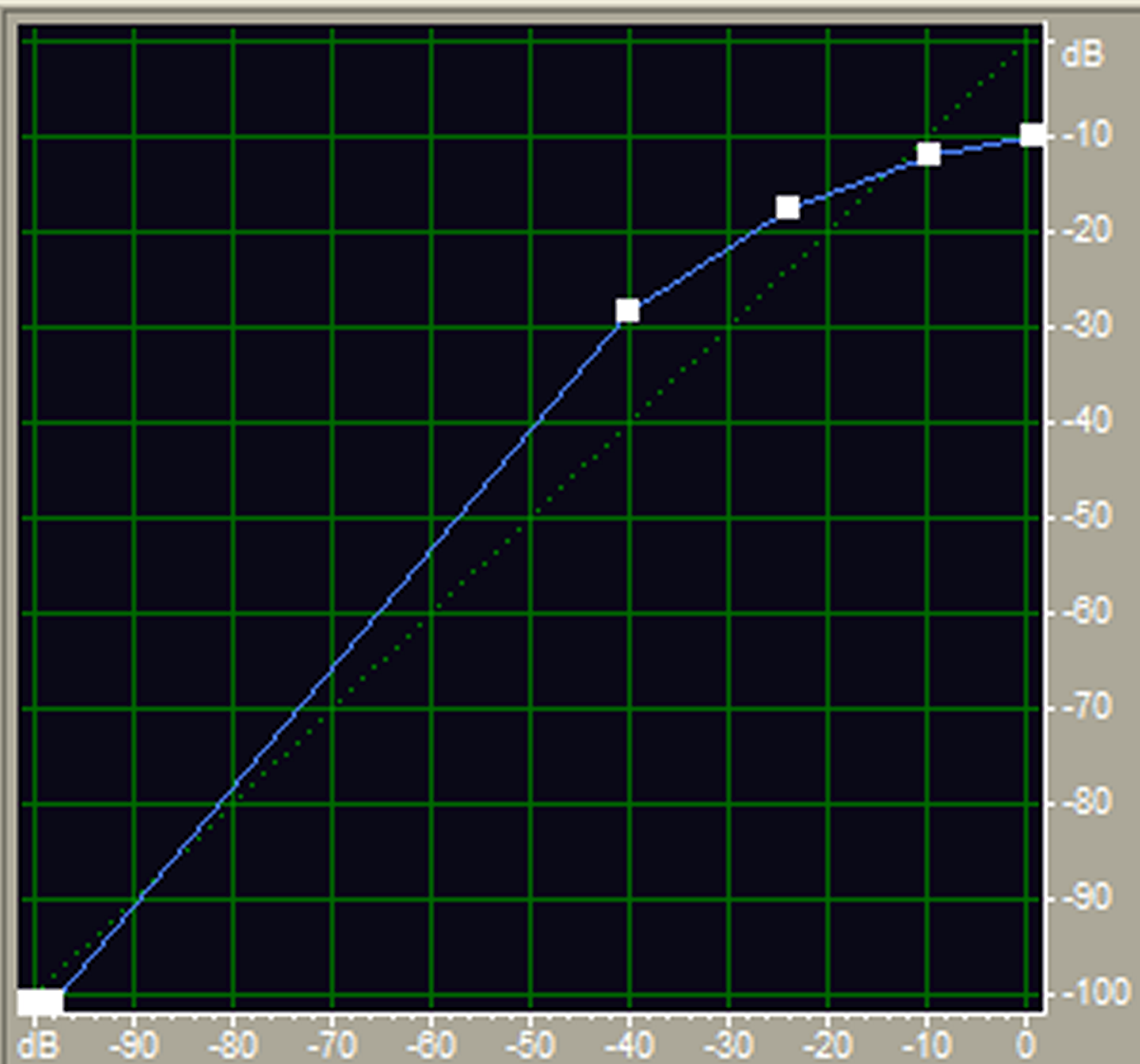 Figure 1 Classic soft-knee
Figure 1 Classic soft-knee
A downward compressor will decrease the overall average level of the signal by decreasing the gain for the loudest parts of the wave. Some processors compensate for this effect by applying “makeup gain” to keep the average level unchanged. Of course, applying makeup gain requires more compression of the loud parts.
Aside from artistic effects when applied to specific instruments in a mix, compression is primarily used for one of two purposes:
- to prevent clipping of the signal
- to allow the operator to raise the average level of the mix.
It does this by decreasing the dynamic range. Figure 2 shows the waveform of an uncompressed choir performance recording. This is a composite wave including all 18 tracks (songs) that were on the CD. As you can see, the average level of music peaks ranges from below -18 to 0 dBFS.
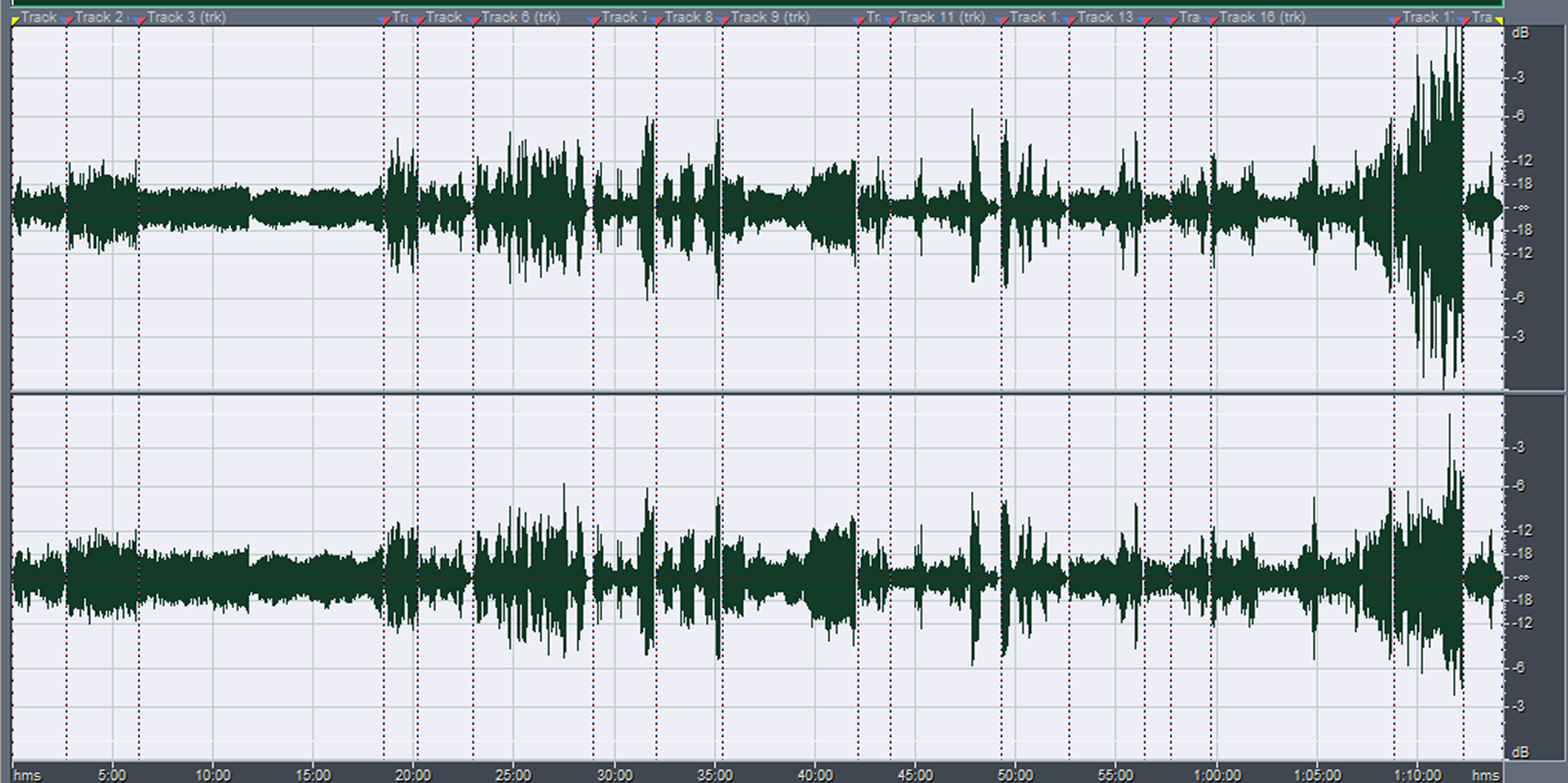 Figure 2: An uncompressed choir recording.
Figure 2: An uncompressed choir recording.
Commercial recordings, especially contemporary music recordings, tend to be significantly more compressed than classical or traditional religious ones. Figure 3 shows a composite wave of all the tracks on a commercial music recording. Although most tracks are highly compressed, four of them are less compressed than the others. When commercially recorded tracks are relatively uncompressed, the reason is usually that these tracks carry emotional content that would be lost if too much compression were used.
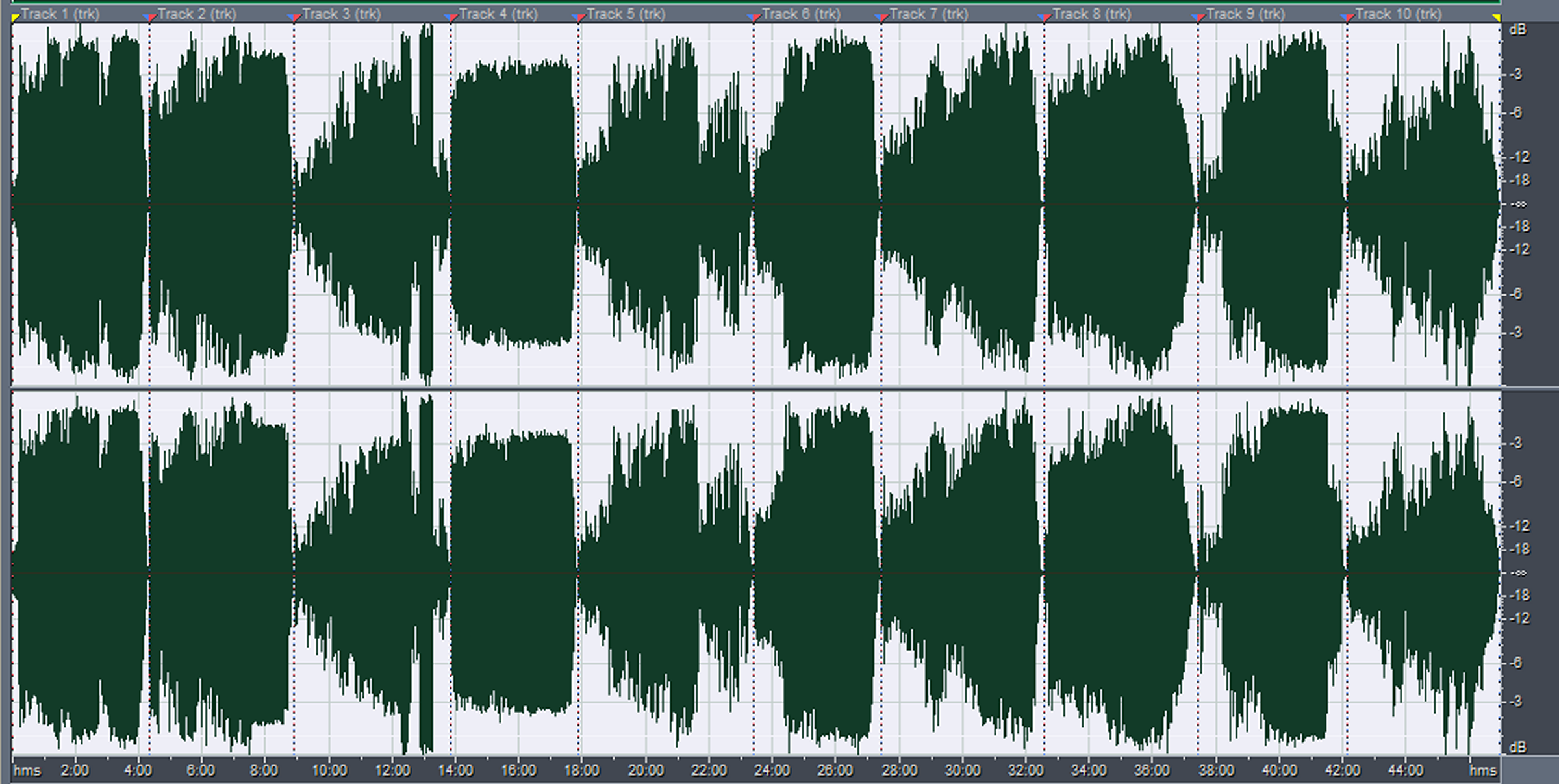 Figure 3: A compressed commercial music CD
Figure 3: A compressed commercial music CD
The average level of the peaks is higher than -3 dBFS, which would make this recording sound about 15 dB louder (perceptually over twice as loud) than the choir recording whose waveform is shown in Figure 2. The loss of musical dynamics entailed by heavy compression is sometimes considered a necessary sacrifice for the reasons we discussed earlier.
Radio and TV programs are often very heavily compressed, so that the waveform looks like a ribbon. The reasons for this are threefold.
- First, in the days of AM radio, station managers and engineers believed that when a potential listener tuned across the dial, (s)he would select the loudest station, and so commenced the “volume wars” in which loudness was equated with profitability.
- Second, since many people listened to radio in their cars, higher average level was considered necessary to drown out road noise.
- Third, especially in the early days of TV, the audio system was noisier than that of a good FM radio, although not as noisy as AM radio. So louder audio helped improve signal-to-noise ratio.
Excessive compression is illustrated in Figure 4. If you would like to hear what this overcompression sounds like, check out http://www.youtube.com/watch?v=3Gmex_4hreQ.
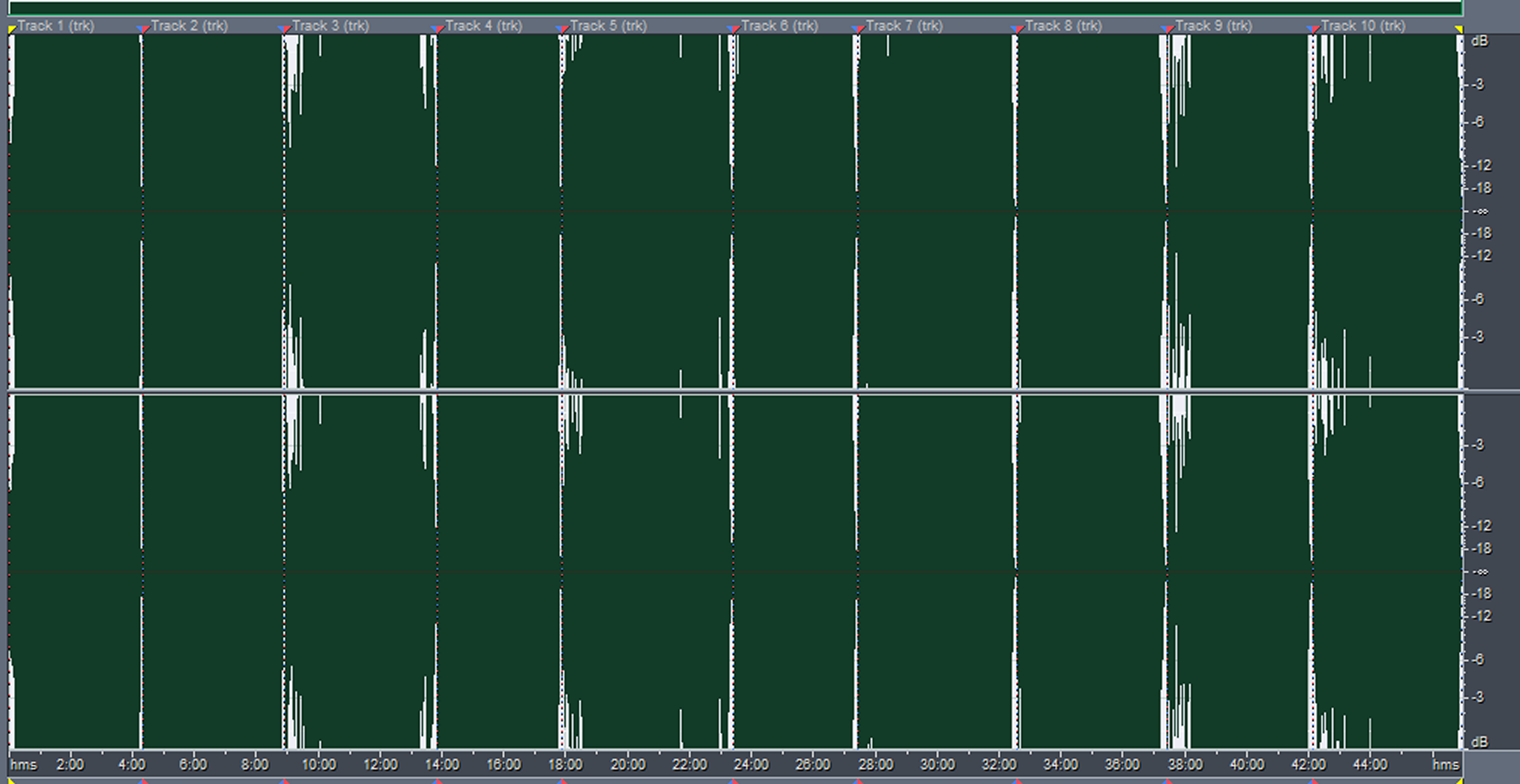 Figure 4: An overcompressed “ribbon” waveform
Figure 4: An overcompressed “ribbon” waveform
Compression rarely helps in live sound, because raising the average level may cause feedback squeal. Two exceptions are when miked loud drums or shouting presenters’ voices must be tamed to avoid annoyance or damage to hearing or equipment. In these cases, only downward compression is helpful. rh
 Richard A. Honeycutt developed an interest in acoustics and electronics while in elementary school. He assisted with film projection, PA system operation, and audio recording throughout middle and high school. He has been an active holder of the First Class Commercial FCC Radiotelephone license since 1969, and graduated with a BS in Physics from Wake Forest University in 1970, after serving as Student Engineer and Student Station Manager at 50-kW WFDD-FM. His career includes writing engineering and maintenance documents for the Bell Telephone System, operating a loudspeaker manufacture company, teaching Electronics Engineering Technology at the college level, designing and installing audio and video systems, and consulting in acoustics and audio/video design. He earned his Ph.D. in Electroacoustics from the Union Institute in 2004. He is known worldwide as a writer on electronics, acoustics, and philosophy. His two most recent books are Acoustics in Performance and The State of Hollow-State Audio, both published by Elektor.
Richard A. Honeycutt developed an interest in acoustics and electronics while in elementary school. He assisted with film projection, PA system operation, and audio recording throughout middle and high school. He has been an active holder of the First Class Commercial FCC Radiotelephone license since 1969, and graduated with a BS in Physics from Wake Forest University in 1970, after serving as Student Engineer and Student Station Manager at 50-kW WFDD-FM. His career includes writing engineering and maintenance documents for the Bell Telephone System, operating a loudspeaker manufacture company, teaching Electronics Engineering Technology at the college level, designing and installing audio and video systems, and consulting in acoustics and audio/video design. He earned his Ph.D. in Electroacoustics from the Union Institute in 2004. He is known worldwide as a writer on electronics, acoustics, and philosophy. His two most recent books are Acoustics in Performance and The State of Hollow-State Audio, both published by Elektor.